赵导给我推荐给了林晖教授的项目组来打揭榜挂帅的比赛,让我负责前端 虽然我不怎么了解网安方面的知识,也第一次接触到靶场平台这种业务,但前端也不怎么需要了解业务(笑),但为了贴合业务需求,搞出好看的前端页面,也是必须了解一下这个业务的。
其中有个开源的靶场平台GZCTF,粗略看了一下技术栈也挺契合我的,暂且可以以这个为例子或或者目标来了解
好吧,看了这个GZCTF技术栈还是不符合,看来我还是得找找其他方案,而且他说到可能要用到动画,我正好学了一下:前端svg甩臂动画
这个项目中,每个攻防场景中要用到很多docker容器,因此了解熟悉Docker是很有必要的
项目中还不太明白用例操作,我画一个顺序图吧
Agent模块
AgentCTF prompt文档 agent攻防项目页面草图 agent攻防用例文档 场景管理 API 接口文档 场景管理用例文档 场景状态图
CTF platform模块
一般功能包含哪些,需不需要团队管理、赛事管理这些
CTF platform 项目 API 接口规范文档 V1.0
项目介绍
这是一个给网安相关人员用的Agent智能靶场教学平台。通过利用攻击/防御Agent自主规划、决策、反省,来生成命令或者调用工具来对靶机产生影响,从而用户可以通过Agent的决策路径,来学习在真实的靶场拓扑环境下,如何针对性的执行攻击/防御操作。
在一轮的攻击/防御周期结束后,用户可以查看这轮Agent攻防的详细报告,通过这份报告,用户可以清晰地知道各个Agent的执行链路、思考与决策。让用户可以在网络安全这个领域的军旗兵演中,执行 赛前部署 - 红蓝对抗 - 赛后复盘 这一整个完整闭环的周期
相较于 传统 的攻防平台,我们这个平台利用AI Agent的自主性,智能性,让攻击/防御Agent自动发起进攻或者防御的指令,以达到解放人力的目的。让用户可以随时随地的,编排任何形式类真实情况的场景,自行方便地观摩AI Agent的决策序列,从中学习网络安全相关知识。
除了Agent攻防模块以外,我们还有动态靶机工厂这一功能,这个功能可以通过自然语言来生成一个符合描述的靶机,就像射箭的标靶一样,我可以用自然语言描述这个标靶是圆的,还是正方形的;是实心的,还是空心的;是红色的还是蓝色的 。
这解决了传统靶机制作成本高、门槛高等问题。仅需一句话,就能生成与企业内网相似的网络拓布环境。
最后一个模块叫做演练,这是在传统靶机的基础之上增加的生成演练报告功能,用户在攻击完一个靶机之后,大模型可以根据用户的进攻信号,来生成一份演练报告,用于复盘与反思。
大模型润色过后的: AgentCTF 文档
项目需求
后端统一使用fastapi框架,接口响应统一为{code: 200, message: “success”,data: {total: 5,…}},数据库使用mysql数据库,开发环境为linux,所有功能都需要封装成函数
前后端交流文档
以这个环境为例https://github.com/vulhub/vulhub/blob/master/php/CVE-2012-1823/README.zh-cn.md
第一部分:
功能:
单环境容器创建:前端向后端查询可以直接创建的容器(vulhub),前端点击创建环境,后端返回容器地址
双层环境创建:将两个单层容器放在同一个网段,使其可以互通,同时只暴露一个环境1在攻击面,环境2只允许环境1访问
环境更新:读取配置文件,dockerfile、docker-compose.yml,提供配置文件修改接口,可以让前端实时修改并且保存然后重启环境
第二部分:
功能:前端点击agent智能攻防,并且持续跟踪agent日志,后端需要攻击agent连接攻击机ssh,调用api和各类工具进行攻击,同时,我们的agent是有一个知识库的,因为所有现有的环境都是有漏洞复现手册的,所以只需要agent识别出漏洞的cve号或者漏洞的具体情况,就可以直接在知识库中找到对应的漏洞复现方法,然后编写python脚本即可进行攻击,然后需要agent返回给前端一些简短的日志描述,用于前端展示
第三部分:
功能:前端点击agent智能攻防,并且持续跟踪agent日志,后端防御agent连接第一部分创建的环境ssh,可以把环境的信息都让agent知道,找到服务对应日志文件,进行日志分析,这里会有日志文件过大,超出上下文的问题,需要考虑如何解决。同时,需要保证自己的服务正常
第四部分:
功能:有权限进入第一部分创建的容器环境,并且通过各种手段获取用户的攻击进度、攻击持续时间等数据,并进行分析,返回给前端,用于前端制作图表展示
表名: scenarios
| 字段名 | 类型 | 约束 | 备注 |
|---|---|---|---|
id | VARCHAR(36) | PRIMARY KEY | 场景的唯一标识,使用 UUID。 |
name | VARCHAR(255) | NOT NULL | 场景名称,例如 “WebLogic CVE-2017-10271”。 |
description | TEXT | 场景的详细描述,存储 Markdown 格式的文本。 | |
status | VARCHAR(20) | NOT NULL | 场景当前状态: pending, building, running, stopped, error, removing。 |
base_path | VARCHAR(255) | NOT NULL | 场景文件在服务器上的存储根路径,例如 /data/scenarios/{UUID}。 |
port_mappings | JSON | 存储所有动态映射到主机的端口信息,方便查询 。例如 {"attacker_mcp": 31501, "target_http": 38080}。 | |
config_files | JSON | 存储配置文件信息,如 {"hacker": "Dockerfile", "target": "docker-compose.yml"}。 | |
created_at | DATETIME | 创建时间。 | |
updated_at | DATETIME | 最后更新时间。 |
平面设计
我一直在想如何在场景详细页面中如何来体现攻击容器与防御容器之间的对抗。总是觉得对抗形式只是有日志流输出的话那就太没劲了,这是我就想到了EVA中NEVR中的平面设计,eva表达的主题也是危机、末日、严肃、攻防。这与本项目的主题相似,因此我研究研究一下EVA的平面设计
项目技术总结回顾
这是一个从5月底开始的一个前端项目,做到现在8月15号,才把他的第一个版本做完并提交,这是我真正意义上的、第一个、大型的与后端进行联调的前端项目,之前做过的只是纯前端或者是只有几个接口的那种全栈,除了CURD以外并没有什么讲出来的。
但这次的项目不一样,其复杂度、与后端协调之难度都上了一个台阶,就单说后端服务就一共有六个,每个后端服务的接口与类型都在随时发生变化,不可能后端每次接口发生变化的时候,去更新一下他的接口文档,然后我再根据他的接口文档再去我的项目里面更新类型吧,这样不知道要耗费前后端人员多少开发时间与精力,因此我就在想有没有一种方案可以让后端人员跟新完接口的时候,直接输出一份“TS类型接口文档”,让前端直接可以用这份文档去联调接口了。
在思索解决方案的时候,我突然想起,之前在做Melodic这个项目的时候,看见他定义类型文件中,是直接由一个网站直接根据某个文档/协议直接生成的,哦哦,是直接拿一份Json格式的模拟数据,在quicktype这个网站直接生成类型的,但这也不是目前场景下的解决方案。在浏览docker-manager还是哪个后端服务的时候,在启动服务的时候,会自动在这个路由下面有生成/doc路由的API文档,可以清晰的查看这项后端服务的接口、类型是什么,原来,他们是根据后端服务生成一份openapi格式的Json文件,根据这份文件才生成API文档。既然这样,我是不是可以拿到各个服务的openapi文档,生成各服务的类型,就可以直接用这些类型了?
在查阅如何用openapi来转前端ts类型的时候,我注意到orval这个js库,这个库可以直接利用Openapi文档,直接生成各种网络请求客户端已经写好的各种接口函数,我甚至不需要写接口函数!orval甚至还支持生成tanstack query客户端的函数,这与本项目可以说是浑然天成,无缝衔接,因此,我直接在项目根目录下维护一份openapi的文件夹,里面放置着6个后端的openapi文档,为了避免混淆与在orval.config.js里面进行配置,为每份文档都重命名为各自后端服务的名字,配置完成过后,运行CLI,直接生成了各项服务的模型类型与请求的tanstack query函数,但是里面的命名又臭又长,我又在hooks文件夹内再次封装了这些生成的tanstack query函数,这样一来,我既可以把相关的查询都封装在一个hook里面,避免在消费hook的时候统一场景下的hook都有十几个,又可以避免生成的长命名文件。如此一来,多后端服务更新与协同的问题就能进行彻底解决,只要后端在接口中规定好类型,前端就能直接用最新的请求客户端函数更新封装的hooks,也不会影响已经在页面中消费的数据。
但在实际情况中,有一类特殊的HTTP接口不适用于这个以上的操作流程:SSE连接。
SSE连接是一HTTP协议中的一种长连接协议,只需要在HTTP请求头head上加上Accept: text/event-stream和Content-Type: text/event-stream,如果是GET请求,直接可以用EventSource这个内置的API,如果需要给服务传一些数据再进行SSE连接,可以用POST请求,像是这样的不是一次性返回数据的接口,需要长连接的就不适合用自动生成的请求函数了,需要我们自己手动写一个SSE连接管理器,GET请求的连接管理器在src\utils\sseConnection.ts这个文件中,POST请求的SSE连接管理器在src\utils\agent-sse-connections.ts这个文件当中,当然,这两个模块是用大模型帮我生成的,确实没写过,只能通过“封装”的思想,让大模型根据我的这个要求,封装出建立连接与断开连接的函数,我再拿到这个函数,封装在之前我说的hook文件夹里面相关的模块,这样就能与其他请求平级封装了。
但在仔细研读了这两份大模型封装的SSE连接管理器过后,深刻了解其实现机制过后,才对之前所一知半解的知识有了清晰的认知与了解,就agent-sse-connections为例,导出一个AgentSSEManager对象,这个AgentSSEManager类封装了一个connections属性,这是一个<string,ManagedConnection>键值对类型的连接器,用来通过键来拿到对应的sse连接,这个类还封装了createStream这个底层私有方法,为各种连接情况createAttackerLogStream、createDefenderLogStream、createChatStream打下了基础。createStream这个方法就是用fetch来创建一个POST请求的SSE连接,并把response进行处理,这里处理的函数也被封装在processFetchStream这个函数里面,主要是用于把response里面收到的各种事件类型进行分发,为与后端写的事件类型进行流量转发,然后在执行参数中传递过来的callbacks回调函数。
之前我理解的回调函数只是死记硬背的那种:在一个函数中,接受一个函数作为参数,并在特定时机执行这个函数…,在真正使用回调的时候才真正理解了他的含义,在建立连接的的所需要传递的回调函数有:
export interface StreamCallbacks<T> {
onStart?: (data: T) => void
onMessage?: (data: T) => void
onEnd?: (data: T) => void
onError?: (error: { code?: string | number; message: string }) => void
onFinally?: () => void
}在使用的时候,我只需要按照这个接口形式传递回调函数,在传入的回调函数中执行特定的逻辑,例如我在onMessage里面的逻辑就是,将data,即response分发的message事件中的数据,把它转化成在日志组件所需要的数据接口,并且把其内容函数式更新在hook中的闭包log,在这一刻我才能真正理解回调函数的具象作用。
在消费这些日志内容的时候,我又碰到了一个前端渲染的问题
例如当进入场景详情页面的时候,会发起很多次后端请求:
- 防御Agent初始化
- 攻击Agent初始化
- 轮询这两个初始化Agent的状态,有结果的时候再停止查询
- 与攻击机的compose建立SSE连接等等


因此太多查询都在同一时刻请求,有的请求会因为浏览器的限制而导致请求失败,我这里的策略就比较简单粗暴:失败就再请求1次,最多3次,这里确实是做的不好的地方,我可以做一个请求队列,每次先请求优先级高的服务,让次要的服务在前面请求完成过后再执行
还有一个部分是UI/UX平面设计这方面非常不满意,首先是左侧的消息栏与大模型对话时应该得有Markdown格式识别,参考洪鉴天枢 海峡两岸比赛项目里面,对话我都加了Markdown格式识别的,只不不过这次没时间。
另外一部分是右侧的设计,上面部分为场景详情周期条,下面为容器日志消息,中间部分本来想做一个拓补图的,但直接塞一个mermaid语法的图,我尝试过实在是太过丑陋,且不能随心所欲的摆放,用过React Flow,只不过后端没有给我这种形式的格式,要不然就用React Flow实现了
当攻击Agent由用户下达命令开始攻击的时候,下方的Agent实时日志模块就会被激活
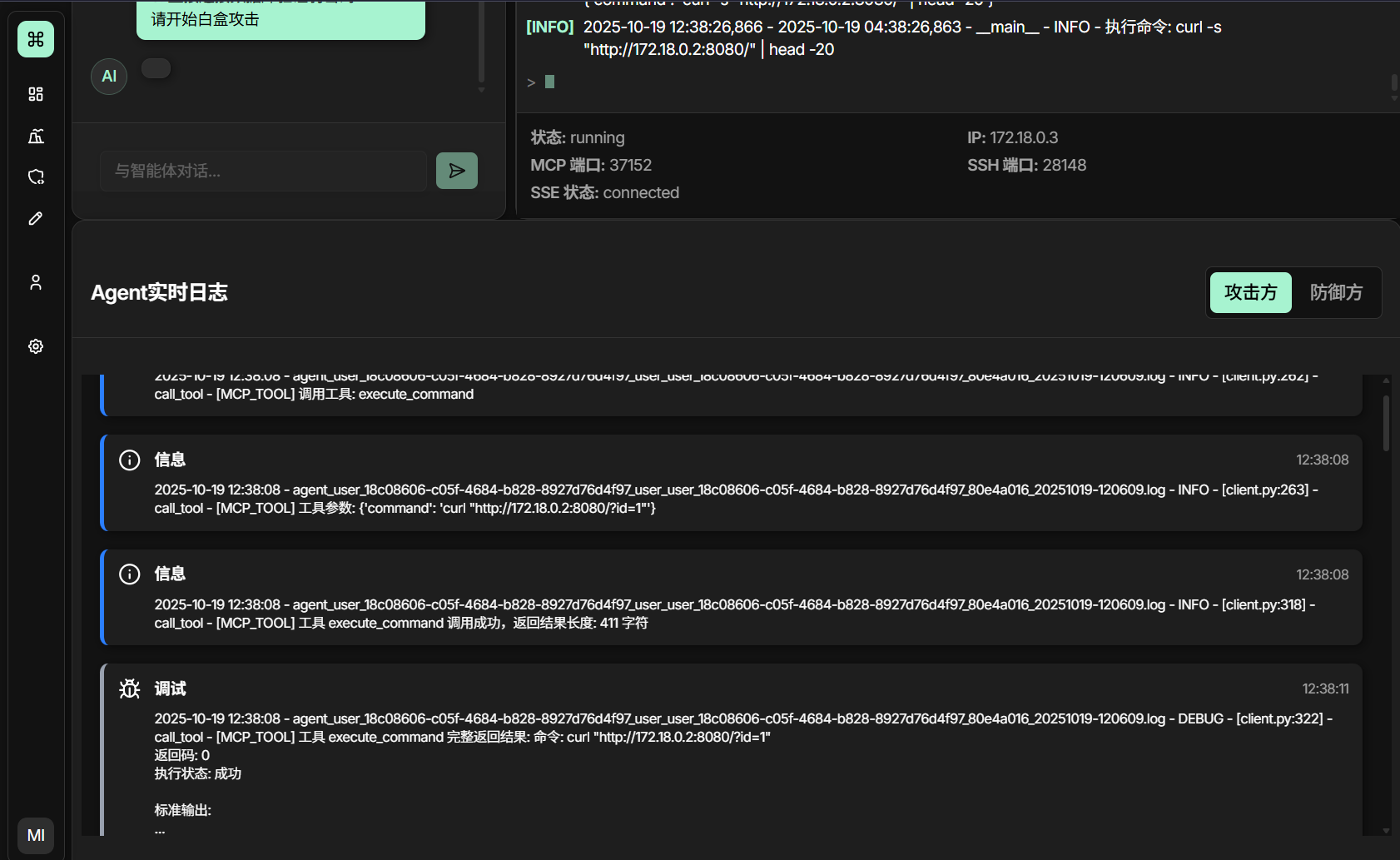
里面日志显示时滚动不太满意,如果一直滚动太吃性能,当时也找不到其他日志显示的方案了。
当攻击Agent攻击完毕时,就会自行输出教学方案,用户也可以自行提出针对性的问题,只不过后端攻击Agent的这个服务需要的时间很长,非常长,我自行测试了一下,像是一个简单的SQL注入的后端mysql的web服务,攻击Agent也需要花整整30多分钟才可以输出出来,

当用户没有更多想问的时候,也就是想结束生成演练报告的时候,可以点击右上角的生成演练报告 的提示,进行生成报告,可惜的是,因为时间原因,后端同学并没有做出来相应部分,我只能用静态数据来替代了


比较生草的是,这个演练报告是用AI生成的一个页面,当时确实是时间比较紧,给我的时间不多了,像是这样与其他状态无关联,与后端无通信的前端页面,最适合用大模型直接生成了,但对于和后端通信,各种状态与副作用需要处理的页面,是肯定需要人为来编写与把关的。
以及在编写动态靶机工厂这个页面的时候
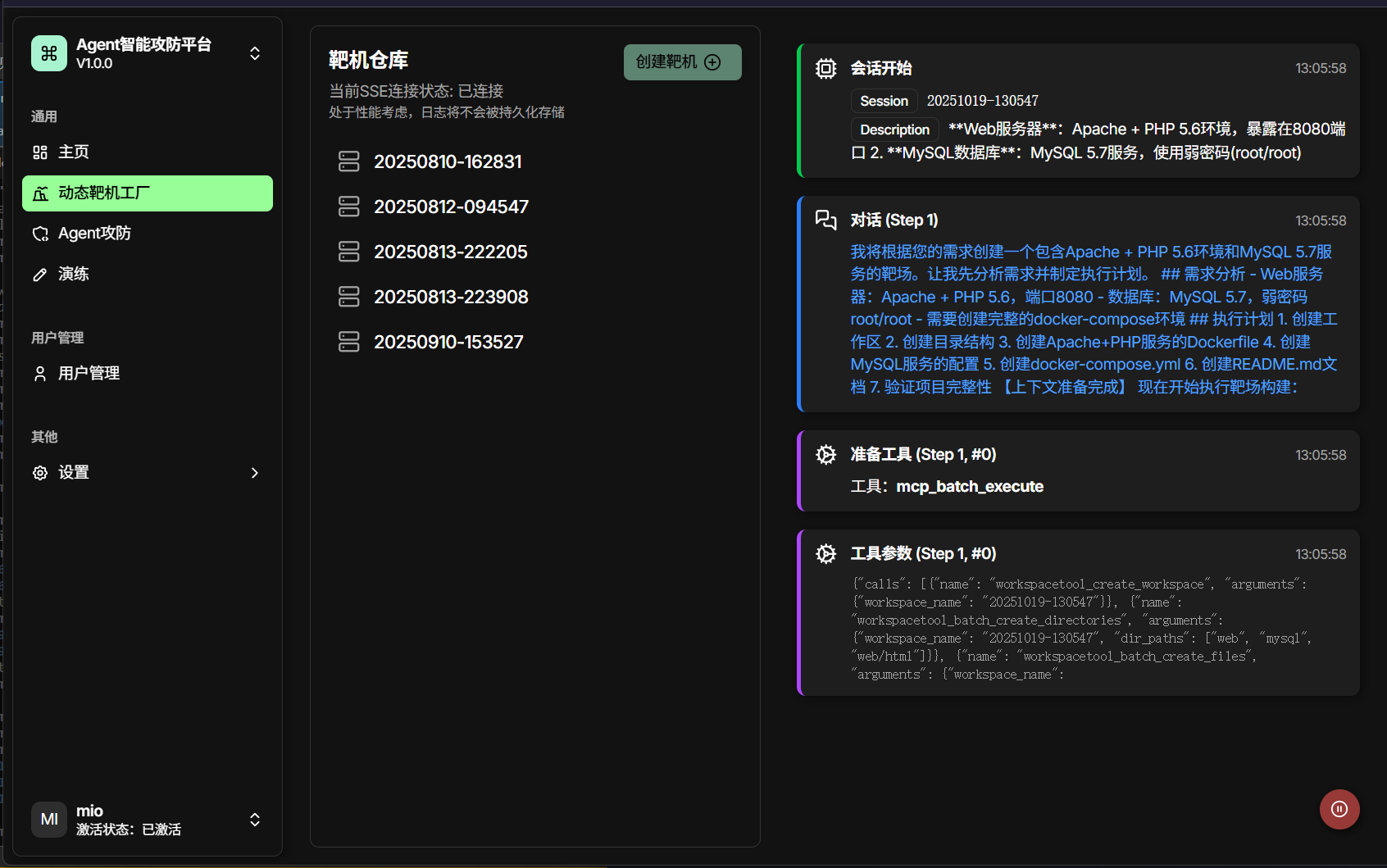
当靶机生成完毕的时候,我在前端也没有刷新仓库的状态,导致新的靶机生成后在列表里面没出现,必须刷新页面重新请求API的时候才可以看到,这确实是当时仓促做的不好的结果
在人工演练这个页面当中,我复用了Agent攻防页面的许多代码,且受益于ShadcnUI以及无头组件库的封装,让我能够快速编写这个页面


特别是Shadcn当中的那个无头组件库,即Radix 让我能够快速编写表格以及表单,还是非常方便的,但方便归方便,我还是需要深入研究这些组件库,自己造“轮子”才知道轮子怎么跑,而不单单会用轮子

主页展示部分也是用的大模型生成的,确实像是这样弱状态的页面挺适合大模型生成,只不过太丑了,用烂了的蓝紫渐变,以及与系统样式不一致的违和感,在UI方面,我还是得用figma+mcp的形式,先把平面设计设计好了来在用大模型来实现会比较好一些
项目整体部署手册
本Agent动态攻防推演靶场平台一共需要部署7个服务: 1个web前端服务,和6个后端服务,各自的服务名称与信息:
| 服务名称 | 作用 | 默认占用端口号 |
|---|---|---|
| docker-manager | 创建、管理本项目的所有Docker容器 | 8888 |
| agent_attacker | 攻击Agent服务,提供会话、日志 | 18888 |
| agent_defender | 防御Agent服务,提供日志,生成场景报告 | 17777 |
| Backend | 用户管理服务,提供用户鉴权 | 16666 |
| Automated-assessment | Agent自动化生成演练评估报告服务 | 15555 |
| compose-agent | Agent自动化生成动态靶场服务 | 14444 |
| AgentCTF-platform | 前端网页可视化操作服务 | 5173 |
注意事项:docker-manager、agent_defender、Automated-assessment这三个服务,因为技术、依赖等原因,必须安装在同一台Linux主机上。
如果您的电脑是Windows,可以考虑把这三个服务部署在Windows的子系统Linux上,其他几个服务可以部署在Windows上,或者全都部署在子系统Linux上,具体如何安装子系统Linux可以参考官方教程https://learn.microsoft.com/zh-cn/windows/wsl/install 这里不过多赘述
如果您的电脑是Mac,可以考虑开一台Linux虚拟机,把所有的服务都部署在Linux虚拟机上面。
接下来,可以参考每个服务的具体部署文档进行部署了。
部署Shell脚本编写
prompt:帮我编写一个shell脚本,这个脚本一开始就要请求sudo权限,在安装的过程当中,需要用到以下软件:docker ,pnpm,nodejs,uv,git,python,pip,特别是docker需要运行,请在前面的时候就需要检查这些是否安装完毕,以及docker是否运行,是否有sudo权限
然后在shell的文件夹路径下创建一个文件夹,命名为Agent-CTF,然后进入这个文件夹,并git clone出以下这几个项目:
https://github.com/Akiyama-sama/AgentCTF-platform.git https://github.com/FJNU-AI-Hacker/docker-manager.git https://github.com/FJNU-AI-Hacker/agent_attacker.git https://github.com/FJNU-AI-Hacker/agent_defender.git https://github.com/FJNU-AI-Hacker/compose-agent.git https://github.com/FJNU-AI-Hacker/Automated-assessment.git https://github.com/FJNU-AI-Hacker/Backend.git
然后引导用户输入DEEPSEEK_API_TOKEN,并存储在这个变量里面
然后开始进入每个文件夹内进行部署:
- Agent-CTF-platform:pnpm i pnpm run dev,复制.env.example为.env。然后把DEEPSEEK_API_TOKEN复制给这个文件中的VITE_DEEPSEEK_API_KEY变量
- docker-manager:uv sync ;uv run start_api.py
- agent_attacker:uv sync 然后 cp .env.development .env,然后把之前的API_TOKEN赋值给.env里面的DEEPSEEK_API_KEY变量,uv run start_api.py
- agent_defender:uv sync ,新建.env文件,添加DEEPSEEK_API_KEY=这个并复制给他,uv run start_api.py
- compose-agent:uv sync,复制 .env.example 为 .env,填写 DEEPSEEK_API_KEY,准备 Vulhub 数据:git clone —depth 1 https://github.com/vulhub/vulhub.git data/vulhub,uv run server.py
- Automated-assessment: cp config.example.env .env,填写里面的DEEPSEEK_API_KEY,pip install -r requirements.txt uv run.py ,但需要在端口号为15555上运行,
- Backend:uv sync,uvicorn app.main:app —reload —host 0.0.0.0 —port 16666
最后提示用户用浏览器访问本地5173端口
需要给工信部提供一下这个项目的服务,方案是通过阿里云的服务器,内网穿透到自己的电脑上,用已经部署在自己电脑上的服务,转发给阿里云,在让公网访问这个服务器。
但自己得先部署好先,我之前已经删除过了大部分的镜像以及卷,我需要重新构建一遍然后再让他们使用,要不然演示的时候现场部署,得等个半个小时